



「SEO対策ひととおりやったけど、検索上位にならない……」
「お店の場所や商品情報を検索結果に表示させたい……」
「構造化データってどれくらい効果があるの?」
WebサイトのSEO対策をいろいろ試していく中で、どうにも思ったように効果がでないと感じる人もいるのではないでしょうか。
SEOはどんな対策をしても結果が反映されるまでには時間がかかり、確実に効果が出るとはいえません。
そうした場合に導入を考えてみたいのが、検索エンジンがよりWebサイトの情報を理解してくれるようになる「構造化データ」です。
この記事では構造化データとはいったい何なのか、導入することでどのようなメリットやデメリットがあるのか、また記述や検証のためにどういったツールを使えば良いのかを、あくまで初心者目線で解説していきます。
「ソースコードのプログラミングまではちょっと手が出ない……」
という人でも、構造化データとはどのようなものなのかを知っておくだけで、今後のSEO対策への展望が大きく違ってくるはずです。
目次
構造化データとは何か

ここでは構造化データとはどのようなものか、そしてどのような考え方に基づいて作られているのかを解説します。
構造化データとは
構造化データとは、Webサイトのテキスト情報を検索エンジンに理解されやすいようにマークアップしたデータのことです。
具体的には、タグ付けによってメタデータを持たせることで、そのテキスト情報が名前や組織、商品、イベント、映画、レシピ、サービス、求人などであることを検索エンジンに理解させます。
たとえば人間であれば「バイト募集!」というテキスト情報から、「この文章はアルバイトの人員を募集しているのだな」と、その意味を理解できます。
しかし検索エンジンは、あくまで単なる「バイト募集!」という文字列としてしか理解できません。
構造化データを用いることで、検索エンジンはその文字列の内容が求人であることを理解できるようになるのです。
セマンティックWebとは
この構造化データのベースには、「セマンティックWeb」という考え方があります。
セマンティックWebはWWW(World Wide Web)の創始者でもあるティム・バーナーズ=リーが1998年に提唱し、同氏が主導する団体W3C(World Wide Web Consortium)が推進してきたプロジェクトです。
セマンティックWebは、Webサイトのテキスト情報にメタデータで意味を与えることにより、検索エンジンに内容を理解させようという考え方です。
これにより、検索エンジンはテキスト情報の意味にくわえて背景や文脈まで理解できるようになります。
そしてこうした理解を蓄積することで、検索エンジンが情報を自ら解釈、処理できるようになってゆくことを目的としています。
その結果として、検索エンジンはよりユーザーに有益な情報を提供できるようになってゆく……という、ある種壮大なプロジェクトなのです。
構造化データのメリット

構造化データにより検索エンジンはどのようなメリットをユーザーに提供してくれるようになるのでしょうか。
構造化データを用いることによって、以下のようなメリットが生じます。
- 検索エンジンにコンテンツが認識されやすくなる
- 検索結果にリッチリザルトが表示される
それぞれ見ていってみましょう。
検索エンジンにコンテンツが認識されやすくなる
構造化データの大きなメリットは、WebサイトがGoogleやYahoo!などの検索エンジンに適切に認識されやすくなることです。
検索エンジンはクローラーと呼ばれるボットによってWebサイトを巡回しています。
このクローリングによって、検索エンジンはどのようなWebサイトがあり、そこにどのようなコンテンツが掲載されているかを認識していきます。
テキスト情報に意味を付与された構造化データは、検索エンジンにその付与された意味を伝達します。
その結果、Webサイトの内容が検索エンジンにより適切に認識されるようになるのです。
検索結果にリッチリザルトが表示されるようになる
構造化データのもうひとつのメリットは、検索結果にリッチリザルトが表示されることです。
リッチリザルトに表示されるのは構造化データでマークアップされた情報で、以下の例では、赤で囲んだ部分がリッチリザルトとなります。

通常のタイルやリンク、メタディスクリプションにくわえてパンくずリストに営業時間、支払方法、予約の可否、連絡先電話番号、評価、価格帯が表示されているのが分かります。
こうしたリッチリザルトは、求人やレシピなどを検索した際にはさらに大きく表示されます。
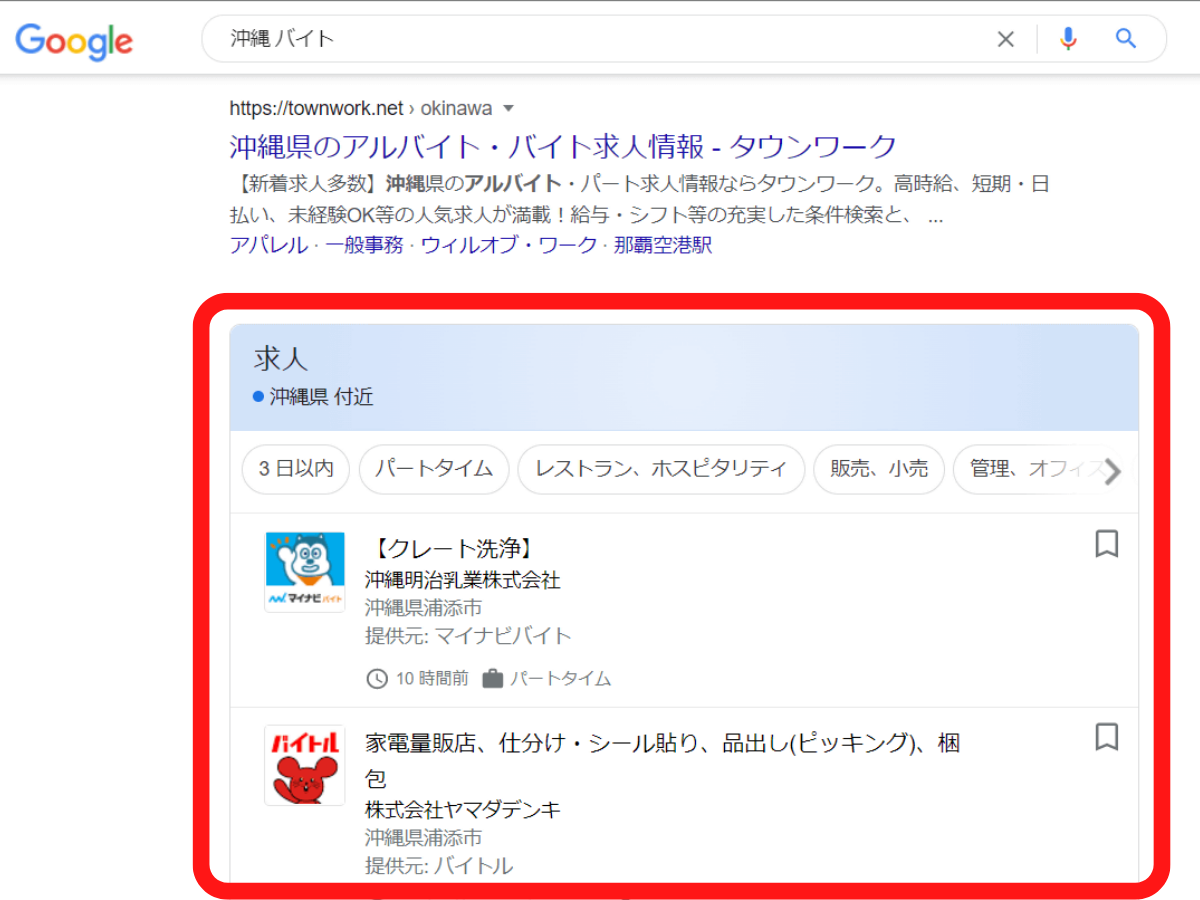
たとえば「沖縄、バイト」で検索してみると、求人情報の仕事内容、企業名、住所、提供元サイト、給与、待遇、掲載時期が一目で分かり、さらに「3日以内」「パートタイム」などで絞り込むことも可能です。
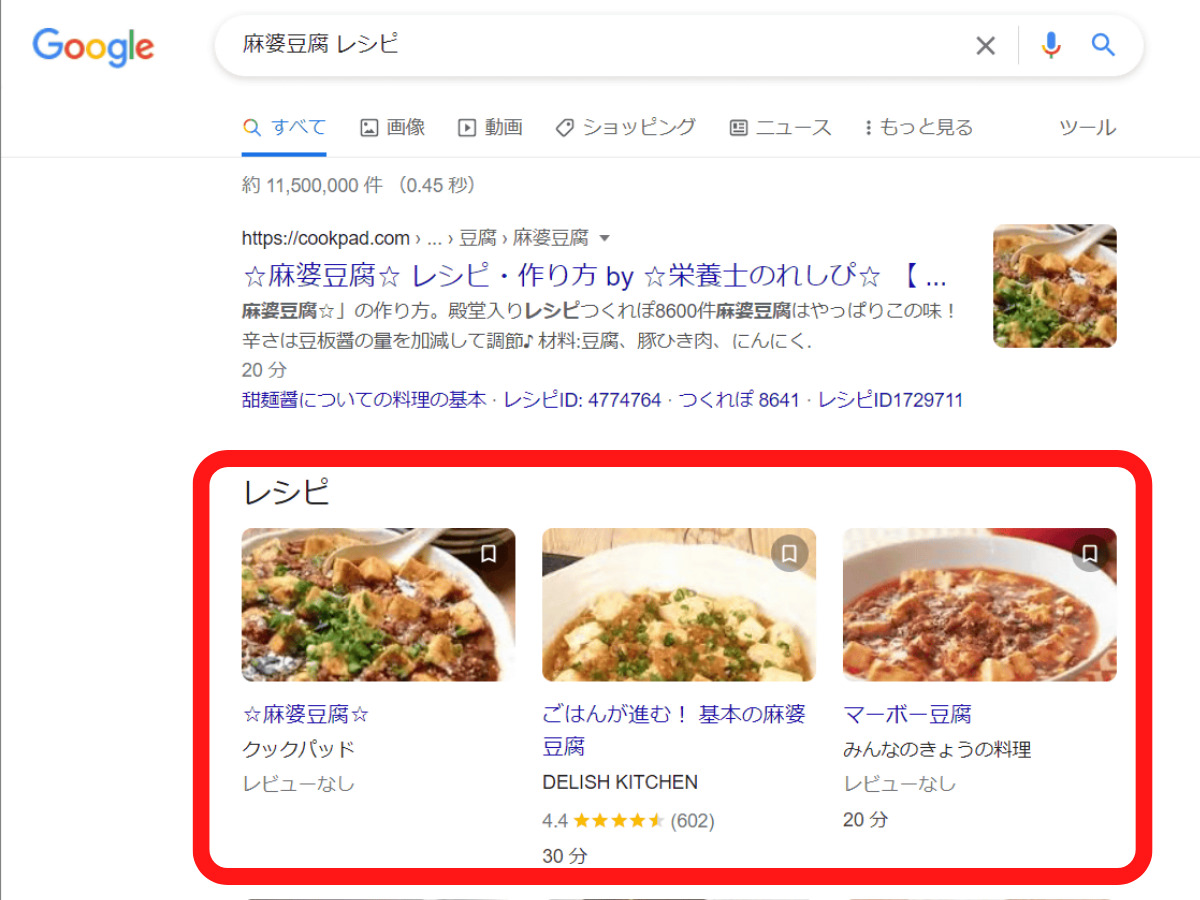
またレシピでは、「麻婆豆腐、レシピ」での検索でこのように料理名、掲載元サイト、レビュー数、評価、調理時間が画像付きで表示されます。
これまでも検索した際に何気なく触れていた便利な情報の多くが、実は構造化データによるリッチリザルトだったのですね。
構造化データのデメリット

構造化データを導入するにあたり、デメリットはないのでしょうか。
実は、実装に際してデメリットが2点あります。
- 専門知識を要する
- 実装に時間がかかる
それぞれ解説していきます。
専門知識を要する
構造化データのデメリットは、実装するためにはマークアップに関する相応の専門知識が必要になることです。
少なくとも、Webサイトのソースコードをなんらかの形で記述したことがなければ自分でマークアップを試すのは現実的ではありません。
専門知識を持つ人に委託するのであれば、もちろんそれなりの費用が発生します。
構造化データは初心者が自分でどうにかできるものでないことはしっかり頭に入れておくべきでしょう。
実装に時間がかかる
また構造化データを実装するには、かなりの時間が掛かります。
マークアップには一定の工数が発生するため、すでに多くのページを有しているWebサイトであれば、実装までの時間はページ数に応じて長くなります。
またその過程で、構造化データの内容が正しいかどうかを検証する必要があり、エラーが出ればその都度修正が必要となります。
このように、構造化データを実装しようとする際には一定の時間が掛かることを念頭に置かなければなりません。
当然ながら、Webサイトの内容が多ければ多いほど、実装までに掛かる時間は長くなってゆきます。
構造化データはSEOにどう影響するか

ここでは構造化データがSEOにどのような影響を与えるのかを見ていきましょう。
まず重要なポイントとして、構造化データをマークアップしても、SEOに関して直接的な効果はありません。
これはGoogleのジョン・ミュラー氏が動画の中で公言しているもののため、少なくともGoogleに関しては公式見解と考えて良いでしょう。
「直接SEOに影響がないなら意味がないのでは?」
と思われる方もいるかもしれませんが、見るべきはむしろ間接的な効果です。
構造化データをマークアップすると、クローラーがWebページ内のコンテンツの情報をより理解しやすくなるため、クローラビリティが向上します。
その結果、マークアップされていないWebサイトよりもコンテンツ情報を正確にインデックスさせることができるようになるため、検索エンジンからより評価されやすくなります。
また構造化データの設定で、検索結果に表示されるリッチリザルトがWebサイトへの流入を増加させるのも大きなメリットです。
多様な情報が検索結果に表示されることでユーザーの目にとまりやすくなり、競合サイトとの差別化やクリック率の上昇につながります。
構造化データ自体が直接SEOに影響しないにせよ、間接的に検索エンジンとユーザーからもたらされるメリットは大きなものといえるでしょう。
構造化データの重要要素

ここでは、構造化データを構成する2つの重要な要素、ボキャブラリーとシンタックスについて説明します。
- ボキャブラリー:構造化データを設定する際、何についての情報化を定義する「規格」にあたるもの
- シンタックス:構造化データをマークアップするための「記述法」にあたるもの
それぞれ、詳しく見ていってみましょう。
ボキャブラリー
ボキャブラリーは、構造化データを設定する際に、何についての情報なのかを定義する規格のようなものです。
例えば人の名前であれば”name”、住所であれば”address”と記述することで、それぞれの情報が人の名前や住所を表していることを検索エンジンに理解させることができるのです。
代表的ボキャブラリー「schema.org」
ボキャブラリーにはいくつか種類がありますが、その代表格が「schema.org」です。
schema.orgはGoogleとYahoo、Microsoftの3社が共同で策定を進めてきたボキャブラリーの規格のことで、日々拡張を続けています。
Googleがサポートしており、マークアップの補助やチェックのできるツールなどを用意していることなどから、利用が手軽なことが特徴です。
schema.orgではマークアップの際に、タイプとプロパティを指定します。
例えば、人の名前(タイプ)には”name”(プロパティ)を、住所(タイプ)には”address”(プロパティ)を設定します。
このようにそれぞれのタイプにプロパティをマークアップしていくことで、構造化データを設定できます。
シンタックス
シンタックスは、実際にマークアップしていく際の仕様で、記述方法のルールです。
Googleがサポートするボキャブラリーschema.orgを記述するシンタックスには以下の3種類があります。
| シンタックスの形式 | 特徴 |
| JSON-LD | ページの見出しまたは本文の <script> タグ内に埋め込まれる JavaScript 表記。このマークアップにはユーザーに表示するテキストをそのまま挿入しないため、ネストされたデータアイテム(Event の MusicVenue の PostalAddress の Country など)を簡単に表現できます。また、Google は、コンテンツ管理システムの JavaScript コードや埋め込みウィジェットなどでページのコンテンツに動的に挿入される JSON-LD データも読み取ることができます。 |
| microdata | HTML コンテンツ内に構造化データをネストするために使用される、オープン コミュニティの HTML 仕様。RDFa と同様に、HTML タグ属性を使用して、構造化データとして公開するプロパティに名前を付けます。通常はページの本文で使用しますが、見出しでも使用できます。 |
| RDFa Lite | 検索エンジンに伝えたいユーザー表示コンテンツに対応する HTML タグ属性を追加することによってリンクデータをサポートする HTML5 の拡張機能。RDFa は一般に、HTML ページの見出しと本文の両方で使用されます。 |
(Google 検索セントラル「構造化データの仕組みについて」より引用 )
Googleはこのうち、JSON-LDでのマークアップを推奨しています。
今後のサポートを考えれば、JSON-LDでアークアップするのが無難といえるでしょう。
代表的シンタックス「JSON-LD」
JSON-LDの特徴として、ソースコードをシンプルにできる、CMSでも使用が可能といった点が挙げられます。
またJSON-LDは他のシンタックスがHTML上で直接マークアップするのと違い、スクリプトを用いて記述するため、HTMLのどこにでも記述できる仕様です。
Google推奨であることにくわえ、これらの特徴から採用するエンジニアが増えています。
構造化データの書き方

構造化データはどのように実装すれば良いのでしょうか。
ここでは構造化データを記述する方法について紹介していきます。
HTML上に直接マークアップする
最もシンプルな方法は、HTML上に直接マークアップすることです。
シンタックスをHTML上に書き込むことで、構造化マークアップができます。
HTMLファイルへの直接マークアップには、まずHTMLファイルが編集できるソフトで、構造化データを追加したいファイルを開きます。
開いたHTMLファイルに書かれてる既存のHTMLコードにシンタックスで構造化データをheadタグ内に追記してゆきます。
当然ですが、この作業を過不足なく行うには相応の専門知識が必要になるため、初心者が試すことはおすすめできません。
マークアップ用ツールを用いる
HTML上に直接マークアップできない初心者でも構造化データを取り扱う方法があります。
それが構造化データのマークアップを支援してくれるツールの利用です。
ここではGoogleの提供する2種類のツールを紹介していきます。
- 構造化データマークアップ支援ツール
- データ ハイライター
さすがにまったくの初心者が使いこなすのは簡単ではありませんが、ツールを用いることで比較的容易にマークアップができます。
構造化データマークアップ支援ツール
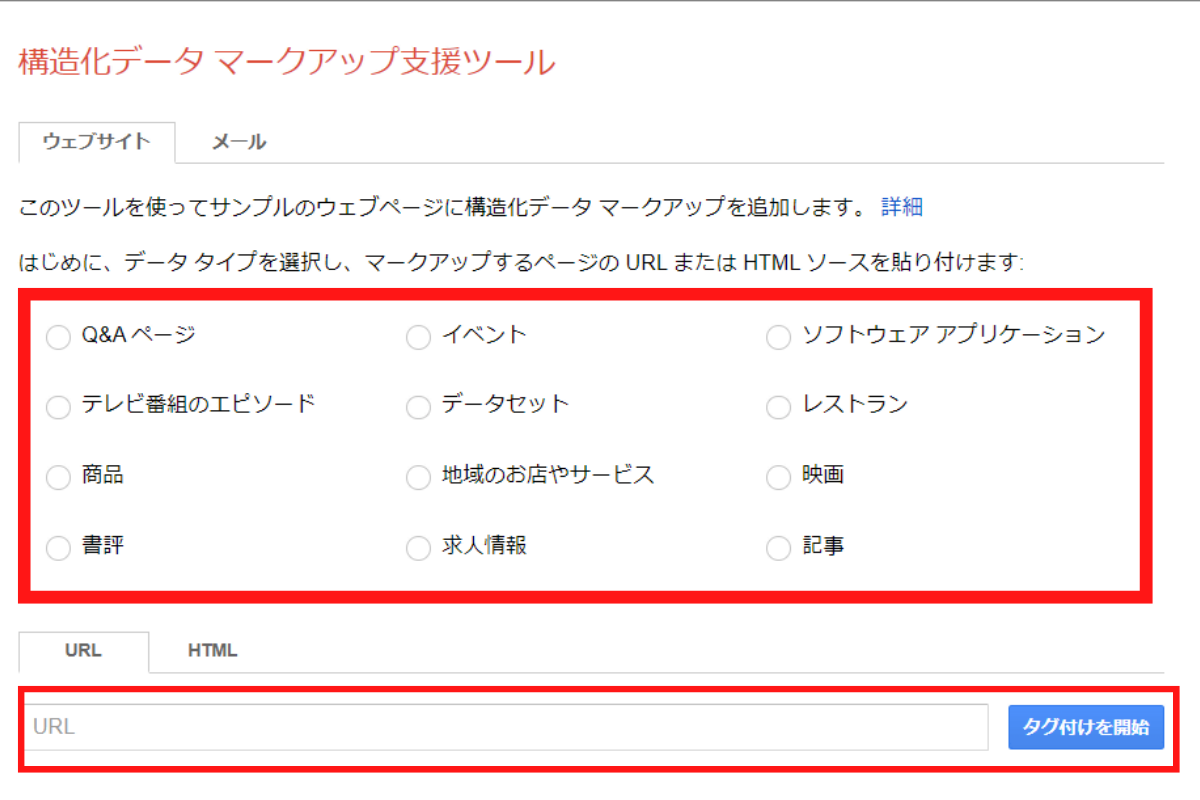
構造化データのマークアップ用のツールでは、Googleの「構造化データマークアップ支援ツール」が便利です。
このツールを用いれば、画面上の簡単な操作だけでサイトに合わせた構造化マークアップが可能となります。
ただし使えるタイプは一部に限られているため、フルスペックの構造化データの設定はできないため注意が必要です。
使い方としては、まずGoogleアカウントで構造化データマークアップ支援ツールのページにログインします。
次にデータタイプから、Webサイトが該当するジャンルにチェックを入れましょう。
その後対象となるWebサイトのURLを入力し、「タグ付けを開始」ボタンをクリックします。
ページ上でハイライトを付与して「何の情報か」を選択し、「HTMLを作成」で構造化データを生成します。
生成されたデータを「ダウンロード」して保存し、内容をテキスト化することでそのままソースコードに貼り付けられます。
データ ハイライター
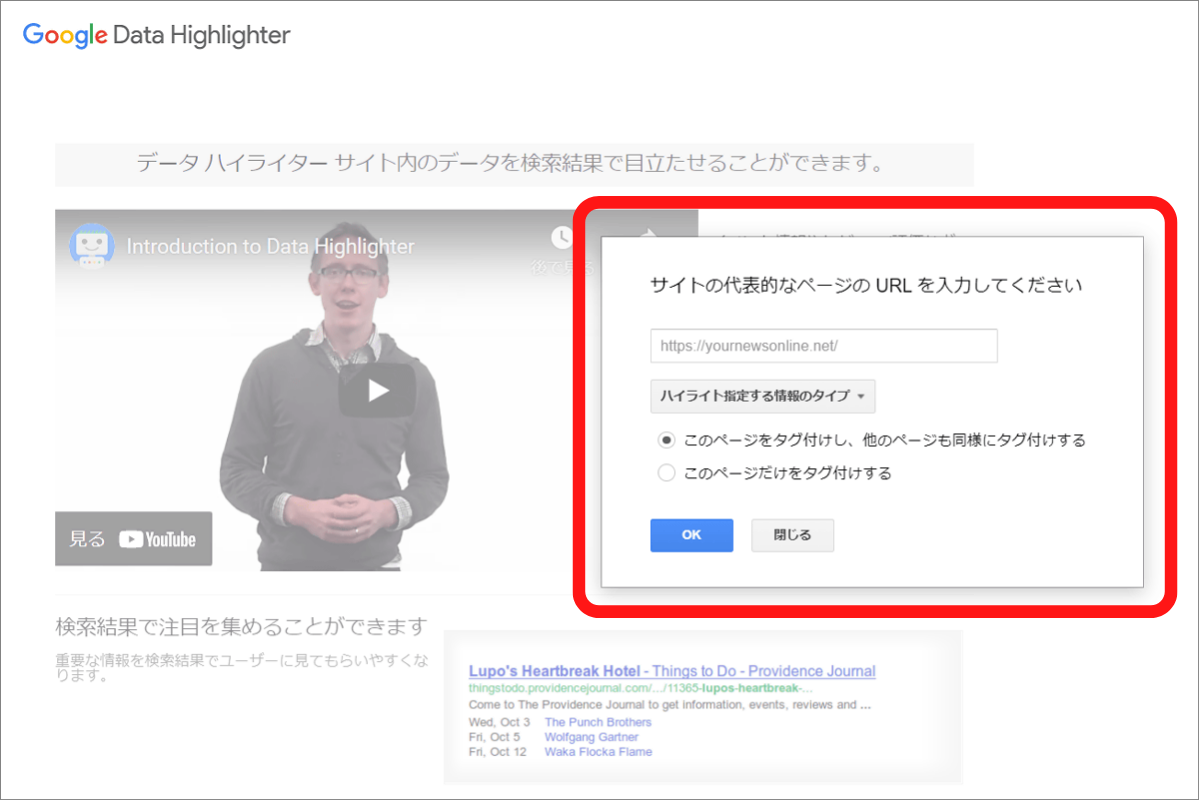
構造化データマークアップ支援ツールでも難しいという人には、同じGoogleから提供されている「データハイライター」がおすすめです。
データハイライターを使えば、直接HTMLをいじる必要が一切なく、構造化データのマークアップからクロールまで一貫して行うことが可能です。
データハイライターの使用手順は、構造化マークアップ支援ツールとほとんど変わりません。
Googleのサーチコンソールから「検索の見え方」を選び、「データハイライター」から「ハイライト表示を開始」の順に進みます。
その後、構造化データを設定したいWebサイトのURLなどを指示通りに入力します。
なおデータハイライターを使う際には、構造化データをマークアップしたいWebサイトをあらかじめサーチコンソールに登録しておかなくてはならないため注意が必要です。
くわえて、URLに規則性がなかったり、HTMLソースが複雑だったりする場合、複数ページをまとめてマークアップすることができません。
構造化データマークアップ支援ツールと同様に、使えるタイプも限られているため、こちらでもフルスペックの構造化データの設定はできません。
構造化データの検証法

構造化マークアップが実装できたら、正しくできているか確認するため、対象ページの構造化データを検証する必要があります。
検証に用いる主なツールは以下の3種類です。
- 構造化データテストツール
- サーチコンソール
- リッチリザルトテスト
それぞれ紹介していきます。
構造化データテストツール
最初に紹介するのは、schema.orgの提供する構造化データテストツールを用いる方法です。
使い方は非常に簡単で、以下のとおりです。
- 構造化データテストツールにアクセスする
- 検証したいWebサイトのURLを入力する
- 「テストを実行」をクリックする
問題がない場合は、「エラーなし」「警告なし」といったテキストが表示され、問題が発生している場合には警告が表示されます。
サーチコンソール
2つ目は、Googleのサーチコンソールから確認する方法です。
サーチコンソールでの検証方法も簡単で、以下のとおりに進めていきます。
- サーチコンソールにアクセスする
- 「検索結果のパフォーマンス」から「検索結果」を選択する
- 「検索での見え方」から「構造化データ」を選択する
構造化データテストツールでは1つのURLしか検証できませんが、サーチコンソールはサイト内の構造化データを一覧で確認できるのが特徴です。
リッチリザルトテスト
最後の方法は、こちらもGoogleの提供するリッチリザルトテストを使うものです。
こちらの検証方法も非常に簡単で、以下のとおりです。
- リッチリザルトテストにアクセスする
- 検証したいWebサイトのURLを入力する
- 「URLをテスト」をクリックする
リッチリザルトテストでは構造化データの検証に加えて、検索結果上でどのように表示されるページかも確認できます。
まとめ
この記事では構造化データの概要や成り立ち、メリットやデメリットから実装方法や実際の書き方、検証方法などを解説してきました。
構造化データはSEOに直接的な影響はないとはいえ、検索エンジンにとってはクローラビリティの向上、ユーザーにはリッチリザルトによる体験の向上をもたらす有効な手段といえるでしょう。
しかし実装には専門知識と時間が必要で、マークアップや検証に便利なツールが提供されているとはいえ初心者が簡単に手を出せる部分ではありません。
弊社BLITZ MarketingはWebマーケティング・Web制作のプロであり、中でもマーケティングに特化したホームページ制作及び運営を得意としております。
構造化データを含むSEO対策により集客を伸ばしたいと考える方はぜひご一報ください。ご相談は無料です。
投稿者プロフィール

- 誹謗中傷対策とWebマーケティングに精通した専門家です。デジタルリスク対策の実績を持ち、これまでに1,000社を超えるクライアントのWebブランディング課題を解決してきました。豊富な経験と専門知識を活かし、クライアントのビジネス成功に貢献しています。








